예측모델(데이터전처리)
이번에는 주식가격(종가)을 예측하는 모델을 만들건데,
결론부터 말하면 데이터셋이 너무 커서 학습시간이 너무 오래 걸리고, loss도 컸고(120억넘음..) 별로 감소하지도 않았다.
그래도 전처리 부분에서 배운게 있으니 이번에는 그 부분을 위주로 보고, 나중에 더 작은 데이터를 가져와서 다시 돌려볼 계획이다.
데이터프레임 만들기
내가 받은 데이터는 케글에서 검색한 미국주식데이터이다. 늘 엑셀로 잘 정리된 파일만 받다가 이런 파일을 받으니 두 가지 문제가 있었다.
1. 폴더 안에 주식별로 txt파일에 날짜, 시작가, 최고가, 최저가, 종가, 판매량, 미결제약정이 써있는 형태
2. 일부 txt파일은 데이터가 없는 빈 파일

file_path = "파일이 들어있는 폴더경로/*.txt"
all_files = glob.glob(file_path)
dataframes = []
for filename in all_files:
try:
df = pd.read_csv(filename)
if not df.empty:
stock_name = os.path.basename(filename).replace('.us.txt', '')
df['Stock'] = stock_name
dataframes.append(df)
except pd.errors.EmptyDataError:
print("skip")
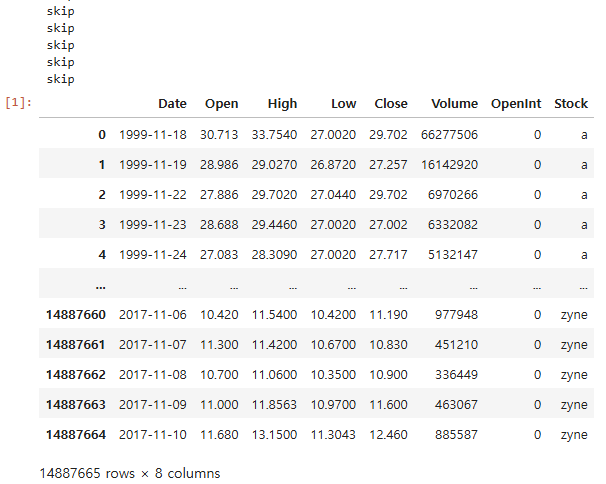
stockdf = pd.concat(dataframes, ignore_index=True)
코드를 끊어서 살펴보면
file_path = "파일이 들어있는 폴더경로/*.txt"
all_files = glob.glob(file_path)
glob.glob는 특정패턴에 맞는 파일들의 경로를 리스트로 반환한다.
glob.glob(경로/*.txt) 라고 입력하면 파일이 들어있는 폴더 내에서 . txt로 끝나는 모든 파일의 경로를 리스트에 넣어준다.
즉 all files=['폴더경로/a.us.txt', '폴더경로/aa.us.txt', ...]
for filename in all_files:
try:
df = pd.read_csv(filename)
if not df.empty:
stock_name = os.path.basename(filename).replace('.us.txt', '')
df['Stock'] = stock_name
dataframes.append(df)
except pd.errors.EmptyDataError:
print("skip")
여기서 try, except는 df = pd.read_csv(filename) 를 처리할 때 오류가 발생할 가능성이 있는 부분을 처리하기 위해 사용했다. 무슨 이유에서든 파일을 읽어올 수 없을 때,
try에서 오류가 발생하면 except로 넘어가서 그 부분이 실행되는 구조
if not df.empty:
df.empty는 df가 비어있을 때를 의미하고 비어있으면 True이다.
if not 이므로 df가 비어있지 않을 때 아래 코드를 실행하게 된다. ->파일을 읽어오기는 했지만 빈 데이터프레임이면 그 이하의 코드는 실행되지 않음
os.path.basename(filename).replace('.us.txt', '')
os.path.basename은 파일의 이름만 가져오는 부분 ex)복잡한폴더경로/a.us.txt ->a.us.txt 이렇게 앞부분 경로가 제거됨
replace('us.txt', ' ') us.txt를 공백으로 바꿈 ex)a.us.txt ->a 이렇게 하면 주식의 이름만 남게 되어서 이걸 stock_name에 저장하고, df['Stock'] = stock_name 을 통해 Stock이라는 컬럼을 새로 만들어서 거기다 stock name을 넣었다.
그렇게 만든 df를 dataframes에 추가하고
dataframes = []
dataframes.append(df)
마지막으로 pd.concat(dataframes, ignore_index=True) 이 코드로 다 합쳐서 하나의 데이터프레임으로 만들었다.
이후 작업
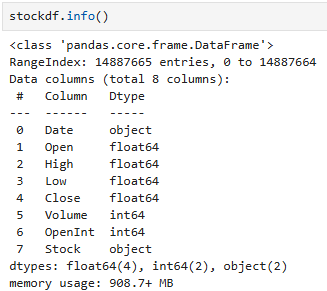
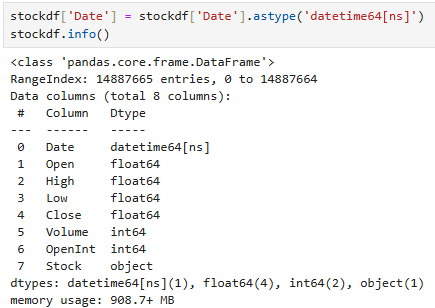
1.date가 날짜형식인지 확인해서 아닐 경우 날짜로 바꾸기
2.openint가 0이 아닌 경우도 있는지 보고 필요없을것 같으면 drop해주기
3.데이터 정규화
1. 날짜형식
2. openint
주가예측에 그다지 영향이 없을 것 같은 항목인데, 우선 0이 아닌경우가 얼마나 있는지 확인했다.


3. 정규화
처음에는 standardscaler를 썼다.
이 때 날짜, 주식이름은 정규화 대상이 아니므로 제외해야한다.

결과를 보면 거의 비슷한것을 알 수 있다.
StandardSclaer는 이상치에 민감해서 갑자기 혼자 튀는 값이 있으면 평균이 왜곡되고 스케일링에 문제가 생긴다.
이럴때는 RobustScaler를 쓰는게 낫다. RobustScaler는 IQR을 사용하기 때문에 이상치에 둔감한편
from sklearn.preprocessing import RobustScaler
scaler = RobustScaler()
stockdf[['Open', 'High', 'Low', 'Close', 'Volume', 'Return']] = scaler.fit_transform(stockdf[['Open', 'High', 'Low', 'Close', 'Volume', 'Return']])
Q return은 뭔가요? >이따설명할게요
데이터의 시각화 그리고 Return
데이터가 너무 많으므로 우선 특정날짜와 특정주식의 데이터만 샘플로 보면
import matplotlib.pyplot as plt
import seaborn as sns
filtered_df = stockdf[(stockdf['Stock'] == 'a') & (stockdf['Date'] >= '2000-01-01') & (stockdf['Date'] <= '2001-01-01')]
plt.figure(figsize=(10, 6))
sns.lineplot(data=filtered_df, x='Date', y='Close')
plt.title("Stock 'a' Close Price from 2000-01-01 to 2001-01-01")
plt.xticks(rotation=45)
plt.show()
df[] 이 []안에서 조건을 줄 때는 and, or 대신 &, | 등을 사용해야 한다.
a주식의 2000년 주식변화만 보면
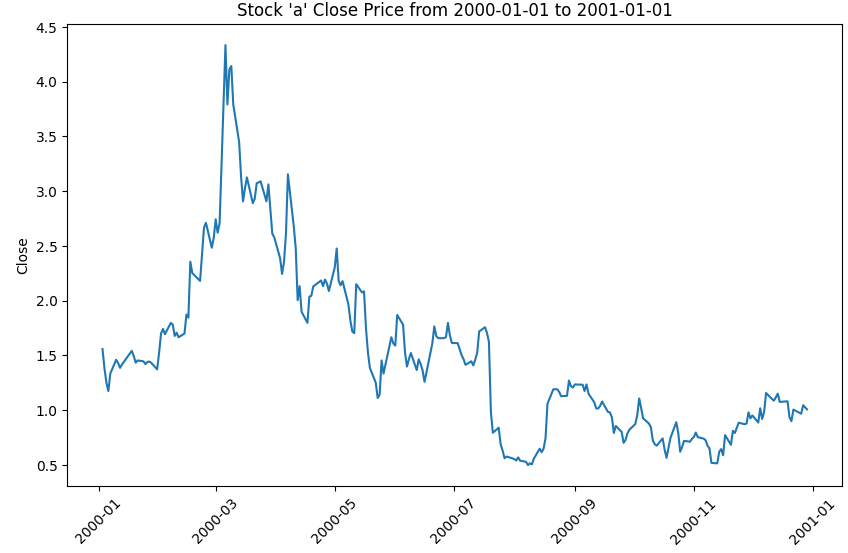
코드를 응용해서 모든 주식의 1년간 주가를 볼 수 있을까?
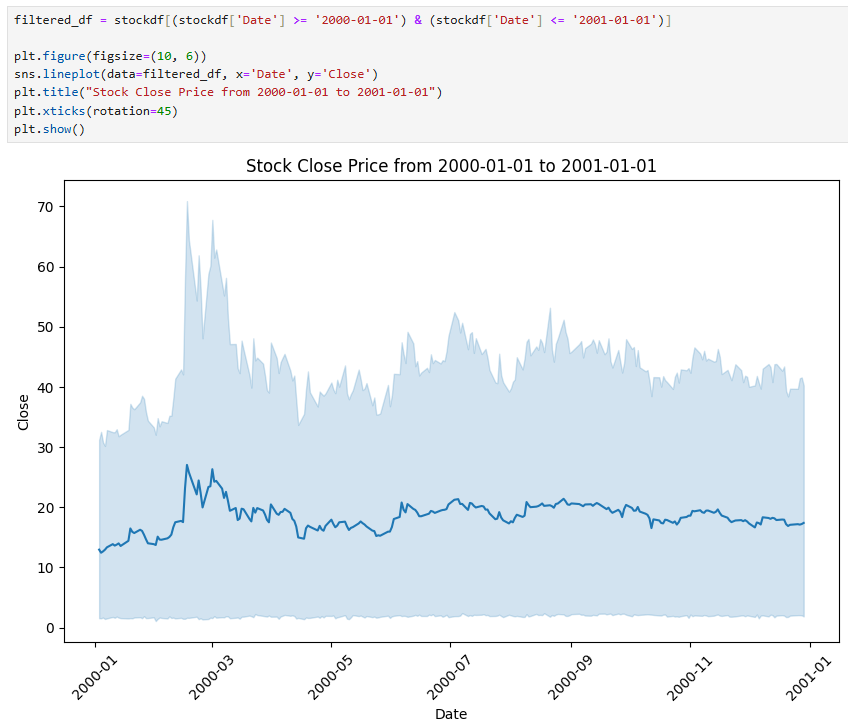
주식이름만 뺐더니 이런 결과가 나왔다.
진한 파란선은 모든 주식의 평균종가이고, 연한파란색은 그들의 신뢰구간(confidence interval, ci)이다.
신뢰구간 표시를 없애려면 ci=none을 입력하고, 모든 주식가격의 개별 흐름을 보려면 hue='Stock'을 입력하면 된다.
filtered_df = stockdf[(stockdf['Date'] >= '2000-01-01') & (stockdf['Date'] <= '2003-01-01')]
plt.figure(figsize=(10, 6))
sns.lineplot(data=filtered_df, x='Date', y='Close', ci=None, hue='Stock')
plt.title("Stock Close Price from 2000-01-01 to 2003-01-01")
plt.xticks(rotation=45)
plt.show()
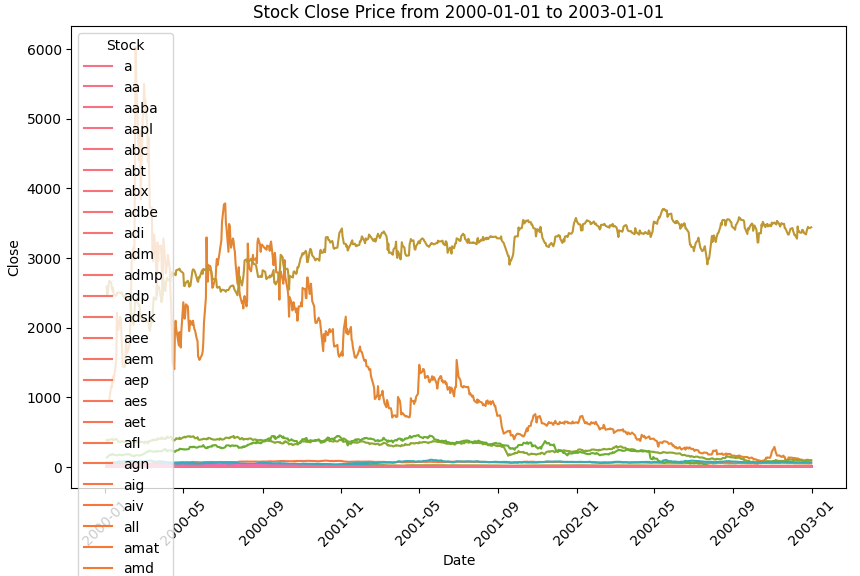
범위를 4년으로 잡아 시각화를 했더니, 보다시피 주마다 변화폭, 최고/최저가에 차이가 크다.
이 데이터를 그대로 학습할 경우 특정 경향에 과적합되거나 변동폭이 큰 주식은 예측을 잘 못할 가능성이 있다.
이럴때 몇 가지 해결책을 떠올렸는데
1. 변화폭이이나 가격이 높은 주/낮은 주를 구분하여 학습
2. 변동이 거의 없고 가격이 0에 가까운 주는 제외하고 학습
3. 일일수익률을 계산해서 수익률로 학습
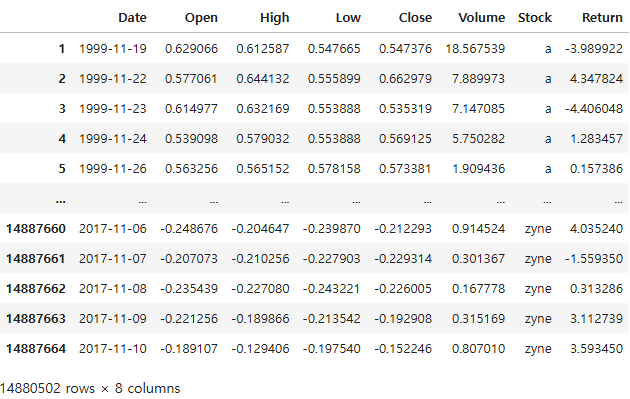
이 중 수익률(Return)을 계산하는 방법을 선택했다.
stockdf['Return'] = stockdf.groupby('Stock')['Close'].pct_change()
stockdf=stockdf.dropna()
pct_change만 해주면 간단하게 수익률이 나온다. pct_change=(다음행-현재행)/현재행 을 계산한다.
이 때 가장 첫번째 날짜는 전날의 가격이 없어 수익률을 계산하지 못하므로 NaN으로 나온다. 그래서 dropna를 해줬다.
주의
이미 robustscaler로 정규화를 했지만, 정규화 전 데이터에서 return까지 계산한 후 return포함해서 정규화를 해주는 편이 좋다. 이미 정규화되어버린 자료로 수익률을 구하면 부정확할 수 있다.
이상치의 발견 및 처리
모델에 수익률을 학습시키기로 했으니, 수익률을 시각화해보자
filtered_df = stockdf[(stockdf['Date'] >= '2000-01-01') & (stockdf['Date'] <= '2003-01-01')]
plt.figure(figsize=(10, 6))
sns.lineplot(data=filtered_df, x='Date', y='Return', ci=None, hue='Stock')
plt.title("Stock Return from 2000-01-01 to 2003-01-01")
plt.xticks(rotation=45)
plt.show()

중간에 혼자 크게 솟은 것이 보인다.
시각화를 하지 않았으면 찾지 못했을 것이다.
의문점> 지금은 4년정도 범위내에서 이상치를 찾았지만, 만약 이 범위안에서 탐지하지 못한 이상치는 어떻게 알아낼 수 있을까? 무작위로 아무 기간이나 시각화해서 계속 이상치를 찾아다녀야 하나?
이상치 처리는 강의에서 배웠던 IQR 방식으로 처리하기로 했다. 더 좋은 방법도 있을것같다.
Q1 = stockdf['Return'].quantile(0.25)
Q3 = stockdf['Return'].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
finaldata = stockdf[(stockdf['Return'] >= lower_bound) & (stockdf['Return'] <= upper_bound)]
이제 코드를 stockdf에서 finaldata로 수정한 뒤 다시 시각화를 해보면
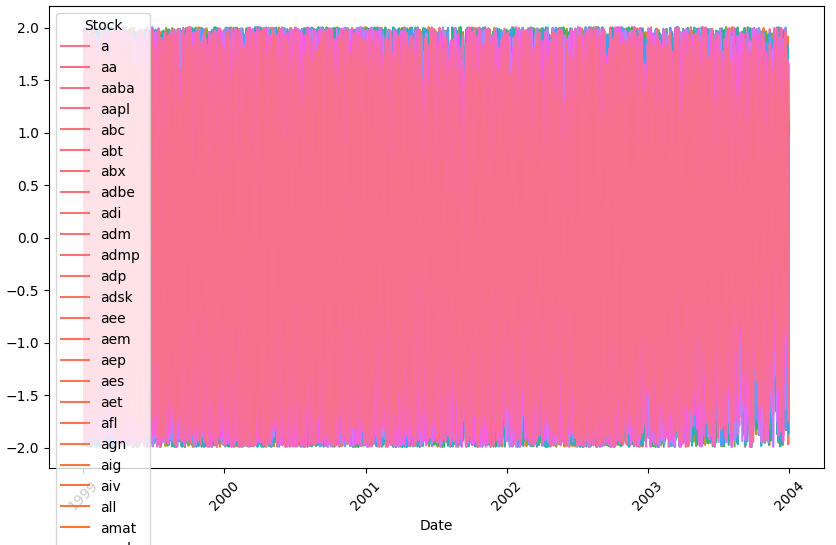
혼자만 튀었던 이상치가 처리된 것이 보인다.
데이터셋 분할(trainset, testset)
보통은 traintestsplit, randomsplit 같은걸 쓸텐데, 시계열데이터는 그럴수없다.
데이터를 시간의 흐름순서로 전달해야 하고, 대체로 과거의 데이터를 학습용으로, 시간순으로 더 미래인것을 테스트용으로 사용한다.
게다가 지금 사용하는 데이터셋은 칠천개쯤 되는, 데이터길이가 제각각인 주식을 다루고 있다.
따라서 주식이름으로 groupby를 하고,
for in 문으로 각자의 길이를 계산한 후, (80:20으로 분할예정)
iloc을 사용해 80% 길이만큼 splicing을 한 다음
trainset과 testset에 각각 넣어줘야 한다.
주식이름으로 groupby
grouped=finaldata.groupby('Stock')
이 때 for in문을 사용하면 반드시
for key, data in df.groupby('Column_name') 의 규칙을 따른다.
key에는 groupby로 지정한 열의 고유값이 들어가고, data에는 고유값의 하위데이터프레임이 다 들어간다.
아래의 코드로 data에 있는것을 확인해보면
for stock, data in grouped:
print(data)

이렇게 stock a의 데이터, stock aa의 데이터... 가 보인다.
우리 목적은 주식마다 데이터의 길이의 80%가 얼마인지 알아내는것이므로
for stock, data in grouped:
split=len(data)*0.8
print(split)

trainset=[]
testset=[]
for stock, data in grouped:
split=int(len(data)*0.8)
train=data.iloc[:split]
test=data.iloc[split:]
trainset.append(train)
testset.append(test)
이제 최종적으로 trainset과 testset을 만들었다.
위의 split 결과를 보면 소수점 형태이므로 int()를 사용해 정수화했고
train은 가장 앞부터 split지점 전까지, test는 split지점부터 끝까지로 했다.
iloc 스플라이싱은 끝점을 포함하지 않음에 주의해야 한다.
이제 만들어진 set을 다시 데이터프레임으로 합쳐주면 된다. (하지만 그냥 리스트형태로 써도 괜찮을거같다..)
traindf=pd.concat(trainset).reset_index(drop=True)
testdf=pd.concat(testset).reset_index(drop=True)
X(input), y(target) 설정
time_steps = 5
X = [train_df['Return'].values[i:i+time_steps] for i in range(len(train_df) - time_steps)]
y = train_df['Close'].values[time_steps:]
X_tensor = torch.tensor(X, dtype=torch.float32)
y_tensor = torch.tensor(y, dtype=torch.float32)
이게 원래 코드인데, 문제가 있다.
데이터가 너무 많아서 메모리에러가 나버린것
아무튼 원래 코드를 살펴보면,
예를들어 i=0이면 X에는 0부터 4만큼의 수익률 자료를 주고 y에는 5이후의 모든 종가를 주고 있다.
즉 y에 X보다 미래의 값을 줘서 과거시점의 데이터 변화를 보고 미래를 예측하도록 학습하는 것
메모리 에러를 해결하기 위해 제너레이터 함수를 정의해서 매번 호출해서 사용하도록 했다.
features=['Return']
#나중에 return말고 시작가, 최고가, 최저가, 종가도 features에 넣어서 더 많은 참고자료로 학습을 시킬수 있게 코드를 짬
def batch_data_generator(df, features, time_steps, batch_size):
for i in range(0, len(df) - time_steps, batch_size):
X_batch = [df[features].values[j:j + time_steps] for j in range(i, min(i + batch_size, len(df) - time_steps))]
y_batch = df['Close'].values[i + time_steps:min(i + time_steps + batch_size, len(df))]
yield torch.tensor(X_batch, dtype=torch.float32), torch.tensor(y_batch, dtype=torch.float32)
이제 모델을 정의하고, 학습시키고 평가하면 된다.
이 코드는 이전 rnn이나 gru 모델과 거의 유사해서 그 부분을 많이 참고했다.
GRU 모델 정의
class GRU(nn.Module):
def __init__(self, input_size, hidden_size, output_size, num_layers):
super(GRU, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
self.gru = nn.GRU(input_size, hidden_size, num_layers=num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(x.device)
out, _ = self.gru(x, h0)
out = self.fc(out[:, -1, :]) # 마지막 시간 단계의 출력
return out
num_layers = 1
input_size = 1
hidden_size = 16
output_size = 1
#input으로 return을 주고 output으로 close를 나오게 설계
#필요시 input을 open high low close volume return으로 늘릴수 있음 inputsize=6
이전과 달라진 점은 num_layers인데, layer를 여러층으로 하고 싶으면 간단하게 num_layers=2 이런식으로 지정해주면된다.
(원래 2로 했는데 로스도 크고 너무 느려서 다시 1로 바꿈)
모델학습코드
sample_size = 10000
traindf_sample = traindf.sample(sample_size, random_state=1)
model = GRU(input_size, hidden_size, output_size, num_layers)
criterion = nn.SmoothL1Loss()
optimizer = optim.Adam(model.parameters(), lr=0.0001)
# 모델 학습
num_epochs = 100
batch_size = 64 # 배치 크기
for epoch in range(num_epochs):
model.train()
# 배치 데이터 로드
data_gen = batch_data_generator(traindf_sample, features, time_steps, batch_size) # 제너레이터에서 배치를 가져옴
epoch_loss = 0 # 에폭당 손실 추적
batch_count = 0 # 배치 수 추적
for X_batch, y_batch in data_gen:
outputs = model(X_batch)
optimizer.zero_grad()
loss = criterion(outputs, y_batch.unsqueeze(-1)) # 출력과 정답의 차원을 맞춰줌
loss.backward()
optimizer.step()
epoch_loss += loss.item()
batch_count += 1 # 배치 개수 증가
# 10번째 에폭마다 중간 결과 출력
if (epoch + 1) % 10 == 0:
print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {epoch_loss / batch_count:.4f}')
print('Finished Training')
처음에는 sample을 하지 않았는데, 전체데이터로 학습하니 너....무 느려서 어쩔수없이 샘플만 뽑아서 돌렸다.
그런데 이것도 느리다.

ㅎ.. 이마저도 학습률이나 배치크기 조정 전에는 120억이었다.
테스트 데이터 준비 및 평가코드
이 부분은 실행은 하지 않고 만들어두기만 해서 오류가 날지도 모른다.
나중에 더 합리적인 데이터를 가져와서 다시 돌려볼 계획이다.
time_steps = 5
features = ['Return']
X_test = [testdf_sample[features].values[i:i + time_steps] for i in range(len(testdf_sample) - time_steps)]
y_test = testdf_sample['Close'].values[time_steps:]
# 텐서로 변환
X_test_tensor = torch.tensor(X_test, dtype=torch.float32).to(device)
y_test_tensor = torch.tensor(y_test, dtype=torch.float32).to(device)
# 모델 평가
model.eval()
with torch.no_grad():
predicted = model(X_test_tensor).cpu().numpy() # GPU에서 CPU로 변환
true_values = y_test_tensor.cpu().numpy() # GPU에서 CPU로 변환
# 시각화
plt.figure(figsize=(10, 5))
plt.plot(true_values.flatten(), label='True') # 실제 값
plt.plot(predicted.flatten(), label='Predicted') # 예측 값
plt.legend()
plt.title("Stock Price Prediction")
plt.xlabel("Time Steps")
plt.ylabel("Normalized Price")
plt.show()
용?두사미로 끝난 느낌이지만 데이터크기가 이렇게까지 클 줄 몰라서 어쩔수가 없었다..
그래도 전처리하는 법도 많이 배우고 매번 데이터를 generate하는 함수나 시계열 데이터 다루는 법을 조금 더 알게 되었다.