embedding
문서와 문장을 임베딩하고, 유사도를 비교하고 비슷한 문장을 뽑는 실습
모델과 파일 불러오는 코드
from sentence_transformers import SentenceTransformer
import numpy as np
# 모델 불러오기
model = SentenceTransformer('sentence-transformers/xlm-r-100langs-bert-base-nli-stsb-mean-tokens', device='cpu')
# input.txt 파일 불러오기
with open('input.txt', 'r', encoding='utf-8') as file:
document = file.read()
참고로 input.txt 의 내용은 chat gpt 한테 써달라고 했고, 아래와 같은 네 문단의 글이다.
이순신 장군은 조선 시대의 대표적인 명장으로, 임진왜란 당시 조선을 수호한 인물로 잘 알려져 있다. 그의 전투 방식은 지략과 신속함이 돋보였으며, 특히 거북선을 통해 일본의 대규모 해군을 격파하며 해상에서 우위를 점했다. 이순신 장군의 전투 기록을 살펴보면, 탁월한 전략가이자 민족적 영웅임을 알 수 있다. 그는 백의종군하며 전장에서 스스로의 목숨을 걸고 싸우며 조선의 안위를 지켰다.
임진왜란 동안 이순신 장군이 이끈 여러 전투 중에서 가장 유명한 것은 한산도 대첩이다. 이 전투에서 그는 일본 함대를 한산 앞바다로 유인하여 학익진 전법을 펼쳤다. 이 전법은 적의 함대를 포위하면서 공격하는 전술로, 일본의 함대를 크게 무찌르는 성과를 거두었다. 한산도 대첩 이후 이순신의 명성은 더욱 높아졌고, 그는 일본에 큰 두려움을 심어주었다.
이순신 장군의 리더십과 인품은 조선뿐만 아니라 전 세계에서도 주목받고 있다. 그는 병사들을 아끼고 그들의 사기를 북돋우는 지도자로서 존경받았으며, 그가 남긴 ‘난중일기’를 통해 그의 생각과 마음을 엿볼 수 있다. 난중일기는 임진왜란 동안 이순신이 기록한 일기로, 그의 전술적 지혜와 군사적 판단을 보여줄 뿐 아니라 그의 인간적 고뇌와 애국심을 엿볼 수 있는 소중한 역사 자료이다.
이순신 장군의 업적은 오늘날까지도 기억되고 있으며, 한국의 군사 역사와 민족적 자긍심의 상징으로 남아 있다. 그는 외세의 침략에 맞서 싸운 위대한 영웅으로서, 그가 보여준 애국심과 헌신은 후대에까지 귀감이 되고 있다.
다음 요구사항은

이것인데 무슨말인지 잘 모르겠다. 다른 문서가 뭐지
비교해서 문서의 의미를 얼마나 잘 반영하는지 확인한다는게 무슨뜻인지??
아무튼 문장과 문서의 유사도를 비교하는 코드는 아래와 같이 만들었다.
doc_embedding = model.encode(document)
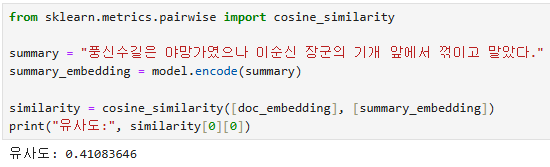
summary = "요약한 문장"
summary_embedding = model.encode(summary)
similarity = cosine_similarity([doc_embedding], [summary_embedding])
print("유사도:", similarity[0][0])
model.encode는 우리가 불러온 모델(sentencetransformer)에서 자연어를 벡터화하는 코드이다.
파일 전체를 인코딩해서 doc_embedding에 저장하고, 문장을 인코딩해서 summary_embedding에 저장했다.
그리고 cosine_similarity를 이용해 두 벡터를 비교했다.
cosine_similarity(vec_A,vec_B)가 있을 때, 두 벡터를 비교해서 유사도를 계산한 뒤, vec_A를 기준으로 가장 유사한 것부터 배열된다.
이 때 비교할 문장이 둘이라면 예를 들어 similarity=[[0.4]] 이런식으로 출력이 되기 때문에,
similarity[0]=[0.4]
similarity[0][0]=0.4 ->즉 숫자만 출력하기 위해 뒤에 [0][0]를 붙였다.
결과
1

2

3
그럭저럭 잘 판단하는 것처럼 보인다.
다음은 글 전체를 임베딩하지 않고 문장으로 나누어서 임베딩을 하고, 비슷한 문장을 검색해볼 것이다.
글을 문장으로 나누는 코드
import nltk
nltk.download('punkt_tab')
from nltk.tokenize import sent_tokenize
# 문장으로 나누기
sentences = sent_tokenize(document)
여기까지 하면 sentences=[문장1번, 문장2번, 문장3번.....문장n]
임베딩 후 유사문장 검색 코드
sentence_embeddings = model.encode(sentences)
example = "예시문장"
example_embedding = model.encode(example)
similarity = cosine_similarity([example_embedding], sentence_embeddings)
similar_idx=similarity[0].argsort()[-1]
print("유사도:", similarity[0][similar_idx])
print("유사한 문장:", sentences[similar_idx])
cosine_similarity를 보면 예시문장은 []안에 들어가있는데, sentence_embeddings는 들어있지 않다.
이렇게 하는 이유?
sentence_embeddings는 이미 토크나이저가 문서를 문장으로 나눠서 리스트로 반환했고, 그걸 그대로 임베딩했으니 [[문장1의 벡터],[문장2의 벡터]....[문장n의 벡터]] 이런 구조
하지만 example_embedding은 하나의 문장을 임베딩해서 [예시문장의 벡터] 이와 같은 구조
둘의 차원을 맞춰주기 위해 example_embedding 을 []에 넣었다.
만약 문서 안에 10개의 문장이 들어있다고 하면, sentence_embeddings에는 10개 문장을 벡터로 변환한 결과가 들어있다.
cosine similarity는 그 10개의 벡터와 예시문장의 벡터를 비교해서, 예시문장과 얼마나 비슷한지를 유사도를 행렬형태로 반환한다. 예를 들면 similarity=[[0.1, 0.5, 0.5, 0.5, 0.3, 0.7, 0.9, 0.4, 0.2, 0.6]] 이런식으로 유사도가 반환되고, 숫자가 클 수록 유사하다는 의미이다.
similarity[0]= [0.1, 0.5, 0.5, 0.5, 0.3, 0.7, 0.9, 0.4, 0.2, 0.6]
argsort() 는 값을 오름차순으로 정렬했을 때 인덱스를 반환한다.
지금의 인덱스는 0번인덱스=0.1 / 1번 인덱스=0.5 /..../ 8번 인덱스=0.2/ 9번 인덱스=0.6 이니까 값을 오름차순으로 정렬하면 [0.1, 0.2, 0.3, 0.4, 0.5, 0.5, 0.5, 0.6, 0.7, 0.9] 이고 이들의 인덱스는 [0, 8, 4, 7, 1, 2, 3, 9, 5, 6]
[-1] 은 리스트의 가장 뒤를 호출한다.
즉 위 예시에서 similar_idx= similarity[0].argsort()[-1] = 6
similarity[0][similar_idx]-> similarity[0][6]=0.9
sentences[similar_idx] -> sentences[6] ->문장7번
결과
1

2

3

4

잘 안되는 것 같은데..?
더 나은 임베딩 모델을 써보거나, 텍스트 전처리를 좀 더 잘 하면 성능이 나올것도 같다.
다음은 문단으로 나눠서 문단간의 유사도를 시각화해보자
문단으로 나누고 임베딩하는 코드
paragraphs = document.split('\n\n')
paragraph_embeddings = model.encode(paragraphs)
PCA로 시각화하는 코드
pca = PCA(n_components=2)
pca_result = pca.fit_transform(paragraph_embeddings)
plt.figure(figsize=(10, 7))
plt.scatter(pca_result[:, 0], pca_result[:, 1], c='blue')
for i, txt in enumerate(range(len(paragraphs))):
plt.annotate(txt, (pca_result[i, 0], pca_result[i, 1]))
plt.title("Paragraph Embedding Visualization using PCA")
plt.xlabel("PCA Component 1")
plt.ylabel("PCA Component 2")
plt.show()
결과

tsne로 시각화하는 코드
tsne = TSNE(n_components=2, random_state=42, perplexity=2)
tsne_result = tsne.fit_transform(paragraph_embeddings)
plt.figure(figsize=(10, 7))
plt.scatter(tsne_result[:, 0], tsne_result[:, 1], c='blue')
for i, txt in enumerate(range(len(paragraphs))):
plt.annotate(txt, (tsne_result[i, 0], tsne_result[i, 1]))
plt.title("Paragraph Embedding Visualization using t-SNE")
plt.xlabel("t-SNE Component 1")
plt.ylabel("t-SNE Component 2")
plt.show()
결과
