정말 다양한 지도학습 비지도학습 앙상블학습 모델들이 있지만 대표적으로 k-means clustering을 보도록 하겠다.
어차피 코드 구성은 거의 비슷하다.
k-means clustering
비지도학습 알고리즘
k: 군집의 개수/means: 평균(군집의 중심점)
k개의 군집중심을 랜덤하게 잡음
각각의 데이터와 군집중심간의 거리를 재서, 가장 가까운 군집중심이 속한 군집으로 데이터를 할
이렇게 생성된 군집 속 데이터들의 평균을 내고, 그것으로 군집중심을 업데이트
더 이상 할당과 업데이트가 일어나지 않을 때까지 반복
그렇다면 k는 어떻게 정할까?
가장 잘 알려진 것은 엘보우방법
k가 커지면 군집 내 데이터와 중심사이 거리가 가까워져 그들사이 총 거리의 합이 줄어든다.
어느 순간 k가 커져도 거리합의 감소율이 급격히 줄어드는 지점이 있는데, 이 꺾이는 지점이 최적k값이 된다.
코드
여기까지는 익숙하게 필요한 것들을 import하고 데이터를 불러왔다.
우선 이전에 많이 했던 전처리들을 보고 가면
결측값 있는지 알아보기
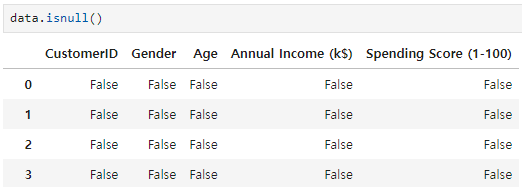
결측값=True, 결측아니면 False로 표시해주는 함수가 isnull() 이였다.

이제 여기에 sum()을 해주면 결측값=True=1이기 때문에 결측값의 수만큼 숫자가 나온다.
같은 원리로 중복이 있는지도 확인해보자

다음은 원하는 데이터 컬럼을 선택하는 작업이다. 데이터를 살펴보니 성별은 숫자가 아닐 뿐더러 숫자로 인코딩 한다고 해도 나이, 수입등 다른 데이터와 크게 연관이 없을것 같다. customer id는 단순 숫자 부여였다는 가정하에 더더욱 연관이 없어 보인다.
이제 스케일링을 해 줄텐데

StandardScaler() 는 어떻게 표준화를 할 지 정하는 도구로, 평균을0, 표준편차를1로 만드는 방법을 정의한다. 정의만 했을 뿐 아직 데이터에는 아무런 변화도 없다.
이후 scaler.fit_transform(data)에서
우선 fit이 data의 평균과 표준편차를 계산하고
transform은 fit이 계산한 평균과 표준편차를 가지고 data를 변환한다.
어떻게? StandardScaler가 정해둔 대로(평균0, 표준편차1)
예를 들어 fit이 계산하기에 data의 평균이5 표준편차가2라면, transform은 데이터에서 5를 빼고 2를 나누면서 평균0, 표준편차가1인 데이터로 변환한다.
그 결과가 밑에 쭉 나와있다.

이제 최적의 k를 찾아야 한다.
우선 inertia=[] 는 관성값을 계산해서 저장할 리스트로, 아직은 비어있다.
관성값이란? 클러스터의 중심점과 데이터사이 거리의 합으로, 클러스터가 잘 나눠지면 이 값은 작아진다.
k=range(1,11) k값을 1부터 10까지의 숫자로 하겠다는 뜻
for k in k: 반복문으로 1부터 10까지의 k에 대해 각각 아래의 코드를 시행하겠다
kmeans=KMeans(n_clusters=k, random_state=42)
Kmeans알고리즘 코드인데 n_cluster= 이건 클러스터의 개수를 결정하는 부분이고 random_state는 앞에서도 했듯 랜덤성 제어를 위해 주는 값이다. 42 말고 다른걸로 해도 되지만 일관된 값을 계속 쓰는게 좋다.
kmeans.fit(data_scaled)
이 때의 fit()은 앞서 StandardScaler에 나왔을 때와 다른 동작을 한다. 지금은 클러스터의 중심을 계산하고 데이터를 할당하는 역할을 해주는 함수이다.
inertia_append(kmeans.inertia_)
이제 inertia라는 빈 리스트에 다음을 추가할텐데(append)
바로 kmeans.inertia_ 즉 데이터와 클러스터의 중심사이 거리의 제곱의 합
이렇게 하면 inertia라는 이름의 리스트 안에 k값에 따른 관성값이 저장되는 것이다.
이제 이렇게 얻어진 inertia로 그래프를 그릴것이다.

최적의 k를 찾았으니 k=5로 하여 군집을 나눠야 겠다.
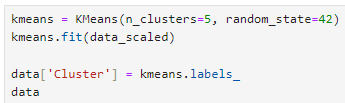
kmeans.labels_ 는 KMeans 알고리즘이 데이터에 할당한 클러스터 레이블(결과)를 의미한다.
이 결과를 data 의 'Cluster'라는 컬럼을 만들어 거기다 저장한다.

이제 이렇게 만들어진 데이터로 산점도를 그려서 x축과 y축을 변화시키면서 실제로 클러스터링이 어떻게 되는지 살펴볼 수 있다.
ex) x=age, y=income인 산점도
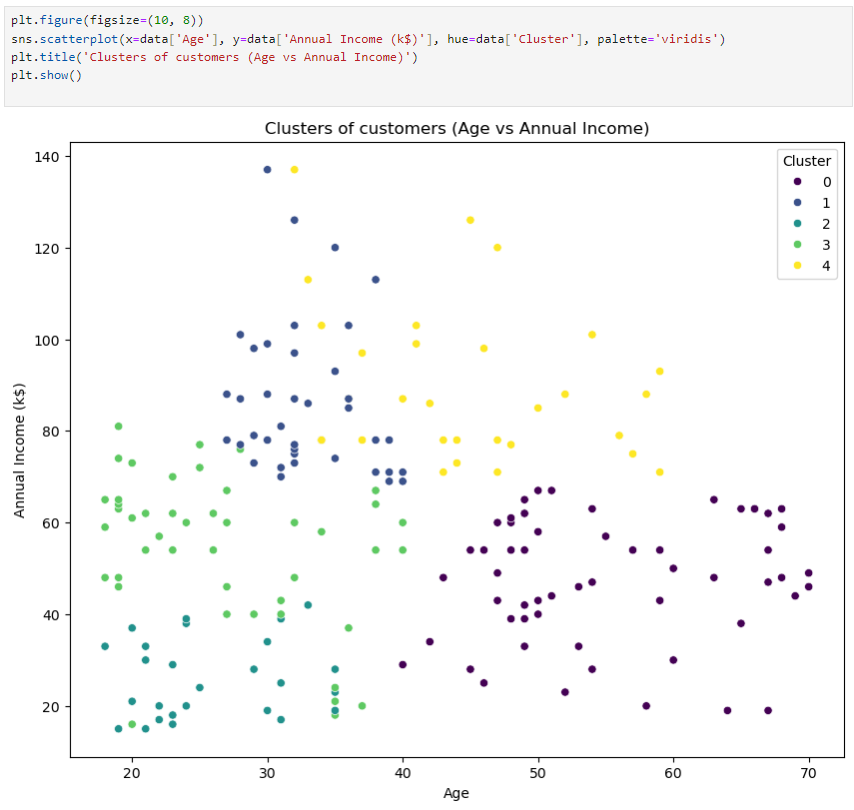
참고로 hue는 클러스터마다 다른 색을 할당해서 시각적으로 구분하는 역할
palette='viridis'는 색상팔레트 지정 옵션으로 hue가 이 옵션에 따라 이 팔레트의 색상으로 표현된다.
'머신러닝' 카테고리의 다른 글
| RNN의 이해 (0) | 2024.10.21 |
|---|---|
| CNN의 이해 (0) | 2024.10.18 |
| ANN의 이해 (1) | 2024.10.17 |
| 간단한 수학 통계 지식(1) (5) | 2024.10.16 |
| 선형회귀, 다항회귀, 로지스틱 회귀 (0) | 2024.10.14 |