지난주말부터 잡고있었던 cat vs dog 구분하는 CNN 신경망
모델은 잘 안되었지만 그래도 새로 배운것들이 몇 개 있어서 포스팅하려고 한다.
ResNet을 사용하면 더 개선될 여지가 있다고 하니 다음번에 시도해보는 것으로..
전체코드
import kagglehub
# Download latest version
path = kagglehub.dataset_download("karakaggle/kaggle-cat-vs-dog-dataset")
print("Path to dataset files:", path)
import torch
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import torch.nn as nn
import torch.optim as optim
# 1. 이미지 변환(transform) 설정 (이미지 크기 조정 및 정규화)
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Resize((256, 256)),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)),
])
# 2. 학습용 데이터셋 불러오기
train_dataset = datasets.ImageFolder(
root='C:/Users/hispa/.cache/kagglehub/datasets/karakaggle/kaggle-cat-vs-dog-dataset/versions/1',
transform=transform
)
# 3. 검증용 데이터셋 불러오기
validation_dataset = datasets.ImageFolder(
root='C:/Users/hispa/.cache/kagglehub/datasets/karakaggle/kaggle-cat-vs-dog-dataset/versions/1',
transform=transform
)
# 4. DataLoader로 배치 단위로 불러오기
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
validation_loader = DataLoader(validation_dataset, batch_size=32, shuffle=False)
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.conv1 = nn.Conv2d(3, 32, 3, padding=1)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(32, 64, 3, padding=1)
self.adaptive_pool = nn.AdaptiveAvgPool2d((16, 16)) # 출력 크기를 16x16으로 축소
self.fc1 = nn.Linear(64 * 16 * 16, 512) # 64채널 * 16x16 크기
self.dropout = nn.Dropout(0.5)
self.fc2 = nn.Linear(512, 2)
def forward(self, x):
x = self.pool(torch.relu(self.conv1(x)))
x = self.pool(torch.relu(self.conv2(x)))
x = self.adaptive_pool(x) # 크기를 16x16으로 줄이기
x = x.view(x.size(0), -1)
x = torch.relu(self.fc1(x))
x = self.dropout(x)
x = self.fc2(x)
return x
# 모델 초기화
model = SimpleCNN()
# 손실 함수와 최적화 알고리즘 정의
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9, weight_decay=0.001)
# 모델 학습
max_batches=32
for epoch in range(5):
running_loss = 0.0
for i, data in enumerate(train_loader, 0):
if i>=max_batches:
break
inputs, labels = data
# 기울기 초기화
optimizer.zero_grad()
# 순전파 + 역전파 + 최적화
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 손실 출력 (매 배치마다 출력)
print(f'[Epoch {epoch + 1}, Batch {i + 1}] loss: {loss.item():.3f}')
print('Finished Training')
correct = 0
total = 0
max_batches=10
with torch.no_grad():
for i, data in enumerate(validation_loader,0):
if i>=max_batches:
break
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f'Accuracy of the network on the 10000 test images: {100 * correct / total:.2f}%')
from PIL import Image
# 이미지 불러올 준비
preprocess = transforms.Compose([
transforms.Resize((256, 256)), # 이미지 크기를 모델에 맞게 조정
transforms.ToTensor(), # 이미지를 Tensor로 변환
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)) # 정규화
])
image_path = " "
img = Image.open(image_path)
input_tensor = preprocess(img)
input_tensor = input_tensor.unsqueeze(0)
#결과 보여주기
model.eval()
with torch.no_grad():
output = model(input_tensor)
_, predicted = torch.max(output, 1)
if predicted.item() == 0:
print("고양이로 분류되었습니다!")
else:
print("고양이가 아닌 것으로 분류되었습니다.")

새로 배운것
transforms.Resize((256, 256))
데이터셋의 사진크기를 일괄로 맞춰주기 위해 사용했다. 이 코드가 없으면 나중에 사이즈 문제로 에러가 난다.
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
괄호안의 숫자는 각각 R,G,B의 평균과 표준편차를 규정하고 있으며, 이 값은 cat vs dog일 때 자주 사용하는 정규화로 알려져있다. 참고로 앞부분 (0.485, 0.456, 0.406) 이 평균, 뒷부분 (0.229, 0.224, 0.225) 이 표준편차이다.
참고로, 과적합방지 기법 중 하나인 데이터 증강도 여기서 이루어진다.
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(30),
transforms.RandomResizedCrop(32, scale=(0.8, 1.0)),
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.2)
이렇게 이미지를 뒤집고 돌리고 자르고 색깔변화시켜서 다양한 이미지를 학습하게 한다.

새로 배운것
self.adaptive_pool = nn.AdaptiveAvgPool2d((16, 16))
x = self.adaptive_pool(x)
기존에는 선형모델에 전달할 때 크기가 얼마나 될 지 직접 계산해서 숫자를 넣었다.
그런데 이미지 크기가 바뀌거나 풀링을 빼거나 추가하면 선형모델에 전달할 크기도 바뀌므로 다시 계산해야 해서 귀찮았다.
그런데 AdaptiveAvgPool2d((숫자,숫자)) 를 쓰면 이미지를 자동으로 괄호안의 크기로 바꾸어준다.
self.dropout=nn.Dropout(0.5)
드롭아웃은 과적합 방지 기법 중 하나이다. 학습할 때는 일정비율의 뉴런을 무작위로 꺼버려서 모델이 특정 뉴런에 과하게 의존하지 않게 한다. 뒤의 숫자 0.5는 50%의 뉴런을 비활성화한다는 의미로, 대부분 0.5를 많이 쓰는것 같다.

새로 배운것
weight_decay=0.001
L2정규화라는건데, 이것도 과적합을 방지하는 방법 중 하나이다. 구체적인 수학적 내용은 너무 복잡해서 가중치 값을 제한하는 방법이라는 것만 이해했다.
max_batches=32
for i, data in enumerate(train_loader, 0):
if i>=max_batches:
break
이건 배웠다기보다는 응용인데, 데이터셋 크기가 커 학습에 시간이 오래 걸리니까 배치개수를 제한한 것이다.
예를들어 내 배치크기가 32인데 사진이 32000개 있으면 배치개수는 32000/32=1000개가 나와서 1에포크동안 1000개의 배치가 모델로 전달된다. 그러면 너무 오래 걸리니까 1000개의 배치가 있더라도 32개 배치까지만 하고 다음으로 넘어가라는 뜻이다.

결과
난리가남

모델의 정확도를 테스트용 데이터셋을 이용해 평가했다. 처참하다
여기도 마찬가지로 데이터셋이 크니까 10개까지만 평가에 쓰도록 제한했다.


여기가 좀 만들기 복잡했는데, 내가 제공한 사진을 모델이 옳게 평가할 수 있을지 알아보는 코드이다.
input_tensor = preprocess(img)
이미지를 그냥 막 넣을수는 없고, 데이터셋을 전처리했던 것처럼 제공할 이미지도 전처리해야한다.
그렇게 전처리하는 부분이 바로
preprocess = transforms.Compose([
transforms.Resize((256, 256)),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])
또 괄호안의 img에 바로 이미지 디렉토리를 넣으면 안되고 open을 통해 이미지를 파이썬의 객체로 만들어야 한다.
이미지 디렉토리는 단순 문자열일 뿐이라서 그걸로는 아무것도 못한다.
마지막으로
input_tensor = input_tensor.unsqueeze(0)
첫번째차원(0)에 배치크기를 추가해준다. 단일이미지이므로 배치크기=1이 된다.
if predicted.item() == 0:
print("고양이로 분류되었습니다!")
이 부분을 보면, 최종예측=0이면 고양이, 1이면 강아지로 구분함을 알 수 있다.
그렇다면 실제로 모델이 cat과 dog을 어떻게 분류하는지 알 수 있는 방법은?
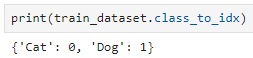
이 코드를 쓰면 된다.
참고로 제일 처음에는 데이터의 폴더구조의 문제로 저 코드를 입력하면 결과는 {'kagglecatsanddogs_3367a': 0}
그러니까 kagglecatsanddogs_3367a 폴더 안에 cat과 dog 폴더가 있고, 모델은 kagglecatsanddoggs 폴더 안의 모든 사진(=cat폴더, dog폴더의 모든 사진)을 다 고양이로 학습한건데, 나는 그 사실을 모르고 있었다.
그래서 학습속도는 엄청 빠르고 손실은 빠르게 0이 되고 accuracy는 100인데
당연히 모델은 내가 제공한 모든 사진을 다 고양이로 분류해버린다.
이 상황을 나는 과적합이 심한 것으로만 보고 자꾸만 과적합 방지 코드를 추가했던 것이다.
다음부터는 폴더구조를 잘 확인하도록 하자...
결과는?
학습률을 만지거나 옵티마이저를 바꿔보거나 뭘 이것저것 해도 모든것을 고양이로 분류하거나 고양이가 아닌것으로 분류해서 차라리 max_batches를 없애버리고 시간이 걸리더라도 다 학습하게 했다.

다시.. 결과는?
뭘 해도 고양이가 아닌 것으로 분류한다..
이럴수가.


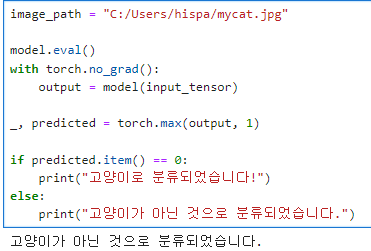

이 외에도 몇 가지 사진을 넣었는데, 다 고양이가 아니라고 한다.
다음번에 더 좋은 모델에 넣어서 다시 학습시켜 보는 것으로..
what's next?
도전과제2
or
skin canccer MNIST