이번에는 넷플릭스 사용자리뷰와 평점 데이터를 받아서
기존 데이터를 학습한 다음
테스트용 리뷰를 주었을 때 평점을 적절하게 예측하는 모델을 만들어 보겠다.
결론: 잘 못만듦
다운받은 데이터
import kagglehub
# Download latest version
path = kagglehub.dataset_download("ashishkumarak/netflix-reviews-playstore-daily-updated")
print("Path to dataset files:", path)
데이터 불러오고 데이터프레임 만드는 부분은 생략하고

전처리까지 마쳐서 이런 데이터를 얻었다.

참고)점수별 리뷰 개수를 보는 방법
value_counts(): 지정한 열에서 고유한 값이 몇 번 등장하는지 세는 함수

reviews=df['processed_content'].tolist()
ratings=df['score'].tolist()
train_reviews, test_reviews, train_ratings, test_ratings = train_test_split(reviews, ratings, test_size=0.2, random_state=42)
이 부분은 testsplit을 사용해서 데이터를 리뷰용과 테스트용으로 나눠주는 코드이다.
바로 testsplit을 쓰지 않고 우선 평가내용(processed_content)과 점수(score)를 리스트형태로 바꿔서(tolist)
각각 reviews와 ratings에 저장해줬다.
리스트 형태의 데이터라야 여러 곳에서 사용하기가 참 편하다.
tokenizer = get_tokenizer('basic_english')
get_tokenizer()는 토큰화함수이다. 괄호안에 사용할 방법을 적어주면 되는데, basic english는 기본적인 영어 토큰화 방법이다. spacy가 더 복잡한 자연어처리를 잘 한다고 들었는데 설치하고 사용하려하니 오류가 계속 나서 basic english를 썼다.
토큰화: 문장을 단어 단위로 나누는 과정
ex) 'I love you' -> ['I', 'love', 'you']
def yield_tokens(reviews):
for text in reviews:
yield tokenizer(text)
yield_tokens라는 이름의 토큰생성기를 정의하는 부분
yield_tokens에 reviews를 전달하면 (여기서 reviews는 reviews=df['processed_content'].tolist() 바로 이 reviews)
reviews 리스트에 있는 항목(text)을 하나씩 tokenizer에 전달해서 토큰을 생성한다.
return 대신 yield
return은 한 번 동작하고 거기서 끝나지만, yield는 매번 호출할 때마다 멈춘부분부터 다시 시작한다.
ex)
reviews=['감동적인 영화!', '배우의 연기가 인상깊어요', '배우의 얼굴이 다 한 영화']
yield_tokens(reviews) -> tokenizer('감동적인 영화') -> ['감동적인', '영화']
yield_tokens(reviews) -> tokenizer(' 배우의 연기가 인상깊어요') ->['배우의', '연기가', '인상깊어요']
yield_tokens(reviews) -> tokenizer(' 배우의 얼굴이 다 한 영화 ') -> ['배우의', '얼굴이', '다' ,'한', '영화']
vocab = build_vocab_from_iterator(yield_tokens(train_reviews), specials=['<unk>'])
어휘집을 만드는 코드
build_vocab_from_iterator <<이 자체가 함수 이름이다.
이 함수는 yield_tokens(train_reviews) 로부터 생성된 토큰으로 어휘집을 만든다. 그리고 각 단어를 고유한 인덱스로 매핑한다. 이 때 어휘집에 없는 단어가 나오면 모두 unk 로 처리하도록 했다.
ex) 위의 예시에서 생성된 어휘집은
vocab=['<unk>', '감동적인', '영화', '배우의', '연기가', '인상깊어요' , '얼굴이', '다' ,'한' ]
이고 이 때 각 단어는 인덱스로 매핑이 되어있다.
즉 print(vocab['영화']) =2 이렇게 인덱스가 붙어있고, 반대로
print(vocab.get_itos()[4])='연기가' 이처럼 인덱스를 사용해서 단어를 불러올수도 있다.
vocab은 언뜻 리스트처럼 보이지만, 단어와 인덱스가 1대1로 매핑되어 인덱스로 단어를, 단어로 인덱스를 호출할 수 있다는 점에서 리스트와는 다른 개념이다.
vocab.set_default_index(vocab['<unk>'])
어휘집에 없는 단어를 만나면 (=할당할 인덱스가 없으면 디폴트로) <unk> 토큰의 인덱스를 반환하도록 설정하는 부분
이게 없으면 어휘집에 없는 단어가 나올 때 에러가 생긴다.

def text_pipeline(text):
return [vocab[token] for token in tokenizer(text)]
텍스트 정보를 어떻게 처리할지 정의하는 부분
tokenizer(text)에서 얻어진 토큰을 -> for token in tokenizer(text)
vocab의 인덱로 반환 -> vocab[token]
ex) text_pipeline('감동적인 영화')
tokenizer('감동적인 영화') -> ['감동적인', '영화'] 이 때 token='감동적인' 과 '영화'
위에서 봤듯이 vocab=['<unk>', '감동적인', '영화', '배우의', '연기가', '인상깊어요' , '얼굴이', '다' ,'한' ] 이었으므로
vocab[ '감동적인' ]=1 , vocab[ '영화' ]=2
따라서 최종적으로 text_pipeline('감동적인 영화') = [1,2]
vocab이 인덱스로 단어를, 단어로 인덱스를 호출할 수 있었다는 점을 생각하면 vocab[token]이 이상하지 않을 것이다. vocab[단어]와 같은 뜻이므로..
def label_pipeline(label):
return int(label) - 1
이것은 단지 위의 표에서 보면 평점이 1점~5점까지로 되어있어서, 이것을 0점~4점으로 맞춰주기 위해 -1을 한 것이다.
int(평점)-> 정수변환
이후에 -1 ->1을 빼기
파이썬의 배열인덱스는 0부터 시작하기에 혼란을 막기 위해 이런 작업을 했다.
참고로, 만약 평점이 4.2 , 1.3 이런식의 연속된 형태였으면 회귀문제로 볼텐데, 1, 2, 3, 4,5 이렇게 떨어져서 5개의 클래스 중 하나를 예측하는 분류문제로 생각했다.
text & label
참고로 파이프라인 뒤의 (text)와 (label) 자리에는 나중에 reviews와 ratings가 들어갈 예정이다.
text와 label은 단지 함수를 정의할 때 쓴 매개변수로, a나 b같은걸로 써도 아무 상관이 없다.
그래도 매개변수 명을 review와 rating으로 했으면 더 직관적이었을 것 같다.
class ReviewDataset(Dataset):
def __init__(self, reviews, ratings, text_pipeline, label_pipeline):
self.reviews = reviews
self.ratings = ratings
self.text_pipeline = text_pipeline
self.label_pipeline = label_pipeline
def __len__(self):
return len(self.reviews)
def __getitem__(self, idx):
review = self.text_pipeline(self.reviews[idx])
rating = self.label_pipeline(self.ratings[idx])
return torch.tensor(review), torch.tensor(rating)
ReviewDataset이라는 클래스를 정의하고 있다.
파이토치에서 데이터셋 정의에 사용되는 torch.utils.data.Dataset 을 상속하고 있다.
class ReviewDataset(Dataset):
def __init__(self, reviews, ratings, text_pipeline, label_pipeline):
self.reviews = reviews
self.ratings = ratings
self.text_pipeline = text_pipeline
self.label_pipeline = label_pipeline
익숙한 초기화 매서드
참고로 self.reviews = reviews에서
앞의 self.reviews는 클래스 내부에서 사용하는 변수이고, 뒤의 reveiws는 외부에서 전달해준 데이터이다.
def __len__(self):
return len(self.reviews)
위에서 reviews는 리스트 형태였다. reviews=df['processed_content'].tolist()
__len__() 매서드는 리스트의 길이를 반환하므로 len(reviews)는 곧 리뷰의 개수를 의미한다.
def __getitem__(self, idx):
review = self.text_pipeline(self.reviews[idx])
rating = self.label_pipeline(self.ratings[idx])
return torch.tensor(review), torch.tensor(rating)
__getitem__() 매서드는 인덱스로 항목을 호출하는 역할을 한다.
호출한 항목을 파이프라인에 전달하고, -> self.text_pipeline(self.reviews[idx])
그 결과를 텐서로 반환한다. -> torch.tensor(review)
ex)
reviews=['감동적인 영화!', '배우의 연기가 인상깊어요', '배우의 얼굴이 다 한 영화']
self.reviews[0] = '감동적인 영화!'
self.text_pipeline(self.reviews[idx]) = [1,2]
[1,2]-> tensor([1,2])
vectorizer = CountVectorizer(max_features=5000)
vectorizer.fit(train_reviews)
countervectorizer는 텍스트를 숫자벡터로 변환한다.
단어의 출현빈도를 기반으로 벡터화하며, max_features를 주면 최대 nn개의 단어만 벡터화하게 된다.
.fit()을 써서 단어에 고유한 인덱스를 부여했다.
BATCH_SIZE=64
train_dataloader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)
test_dataloader = DataLoader(test_dataset, batch_size=BATCH_SIZE, shuffle=False)
데이터셋을 이후 나올 lstm 모델 '학습'과 '평가'에 공급하는 코드
train_dataset = ReviewDataset(train_reviews, train_ratings, text_pipeline, label_pipeline)
test_dataset = ReviewDataset(test_reviews, test_ratings, text_pipeline, label_pipeline)
이것은 ReviewDataset이라는 클래스에 리뷰를 전달해서 데이터셋을 생성하는 과정이었다.
이렇게 생성된 데이터셋 미니배치 단우로 나누어 모델에 전달해서 학습이 효과적으로 진행되게 한다.
여기까지가 사전준비

class LSTMModel(nn.Module):
def __init__(self, vocab_size, embed_dim, hidden_dim, output_dim):
super(LSTMModel, self).__init__()
self.embedding = nn.Embedding(vocab_size, embed_dim)
self.lstm = nn.LSTM(embed_dim, hidden_dim, batch_first=True)
self.fc = nn.Linear(hidden_dim, output_dim)
def forward(self, text):
embedded = self.embedding(text)
output, (hidden, cell) = self.lstm(embedded)
return self.fc(hidden[-1])
이제 LSTM 모델을 정의한다.
class LSTMModel(nn.Module):
def __init__(self, vocab_size, embed_dim, hidden_dim, output_dim):
super(LSTMModel, self).__init__()
self.embedding = nn.Embedding(vocab_size, embed_dim)
self.lstm = nn.LSTM(embed_dim, hidden_dim, batch_first=True)
self.fc = nn.Linear(hidden_dim, output_dim)
기존의 RNN, LSTM 모델과 크게 다르지 않은데,
embedding이라는 부분이 있다.
self.embedding = nn.Embedding(vocab_size, embed_dim)
여기가 바로 임베딩층이다. 임베딩은 의미적으로 가까운 단어끼리 비슷한 벡터로 변환하는 과정이다.
여기서 단어 인덱스를 고정된 차원의 임베딩 벡터로 변환한다.
embed_dim이 바로 고정된 차원이다. 즉 embed_dim=64 라면, 단어는 모두 64차원의 숫자벡터로 변환된다.
ex)
만약 '감동적인'의 인덱스가1 이고, '영화'의 인덱스가2라면 임베딩층을 지나면
'감동적인'=[0.3, 0.4, ......, 0.9] ->64차원의 벡터
'영화'=[0.1, 0.8, ....., 0.6] ->64차원의 벡터
로 변환된다.
이후 lstm과 선형모델을 통과하게 된다. 이 부분은 신경망 모델의 이해에서 계속 다뤘으므로 패스
def forward(self, text):
embedded = self.embedding(text)
output, (hidden, cell) = self.lstm(embedded.unsqueeze(0))
return self.fc(hidden[-1])
역시 익숙한 forward함수이다. 이해가 안가면 RNN의 이해를 다시 봐야 한다.
임베딩 층을 통과시킨 다음, lstm 층에 넣어줄때는 unsqueeze(0)으로 차원을 추가하고 있다.
이후 hidden[-1]로 시퀀스의 마지막 숨겨진 상태를 선형모델에 전달하고 있다.
참고로 hidden[-1]과 output[:,-1,:] 은 동일한 정보를 담고 있다.
단일 레이어로 구성된 경우 output을 사용하면 더 직관적이다.
VOCAB_SIZE = len(vocab)
EMBED_DIM = 64
HIDDEN_DIM = 128
OUTPUT_DIM = len(set(ratings))
사이즈를 정의해주는 부분인데, 주목할것은 하드코딩이 아닌 len을 썼다는 점이다.
len(vocab)은 위에서 생성한 어휘집의 길이
set(ratings)는 ratings에서 중복값을 제거한 것
예를 들어 ratings=[1,2,2,3,3,3,3,2,5,5,4] 일때 set(ratings)={1,2,3,5,4}
len(set(ratings))=5
이후 모델을 초기화하고 손실함수와 옵티마지어 쓰고 학습하는 부분은 이전에 했던것과 거의 비슷하다.
model = LSTMModel(VOCAB_SIZE, EMBED_DIM, HIDDEN_DIM, OUTPUT_DIM)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
num_epochs=100
for epoch in range(num_epochs):
model.train()
running_loss = 0.0
for reviews, ratings in train_dataloader:
outputs = model(reviews)
optimizer.zero_grad()
loss = criterion(outputs, ratings)
loss.backward()
optimizer.step()
running_loss += loss.item()
if (epoch + 1) % 10 == 0:
print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {running_loss / len(train_dataloader):.4f}')
print('Finished Training')
그런데 에러가 난다.
읽어보니 문장길이가 달라서 처리를 못한다는 의미인것 같다.
그래서 패딩이라는 것을 해줘야..한다...

패딩은 문장길이가 짧으면 남은부분은 다 0으로 처리하는 역할을 한다.
ex) reviews=['좋다', '제 인생 최고의 영화였습니다.']
이렇게 차이가 나니까 패딩을 해서 ['좋다',0,0,0], ['제', '인생', '최고의', '영화였습니다'] 로 길이를 같게 맞춰준다.
torch.long은 정수형으로 자료를 쓴다는 뜻이다. 대비되는 개념은 torch.float가 있다.
이렇게 패딩을 적용한 후 dataloader를 다시 정의해서 모델이 학습할 수 있게 해줬다.
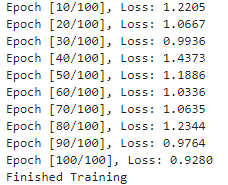

다음은 평가하는 부분인데,
우선 eval()로 평가모드로 들어가야 한다.
그리고 마지막에 prediction +1 을 해서 우리가 원래
def label_pipeline(label):
return int(label) - 1
이 때 1을 뺐던 것을 되돌려줬다.
결과..!






만들면서 많이 배웠다는 점에 의의를 둬야겠다.